Prelude
A key step in becoming a senior programmer creating robust software is the idea of thinking of specification over code.
Yes, this code is correct (or at least it works!), but only under assumptions that aren’t stable guarantees. — Senior Engineer to Junior Engineer
In this post, I’ll use Super Mario pipes as a metaphor to visualize specifications and, with that, something called preconditions and postconditions. Pre and postconditions act as the ‘entrance’ and ‘exit’ guards that the data ‘flowing’ through the ‘pipe’ of your function is correct. This view offers an intuitive way to understand these essential aspects of programming.
Stop Breaking Your APIs Using This One Visual Trick

The primary idea conveyed in The three levels of software is
A program that never goes wrong can still be wrong.
People are often confused when they hear this statement, and rightly so, it does sound strange. So, here is my attempt to create a mental model that will make this statement intuitive. We will harness the power of the pipe to help us reason through program correctness and when changes are breaking or non-breaking.
Pipes and Software | The Three Levels
Let’s start by defining the concepts that we want to visualize. Code exists on one of three levels.
- The runtime level
- The code level
- The logical/specification level
Let’s now use pipes and water to understand and visualize these three levels.
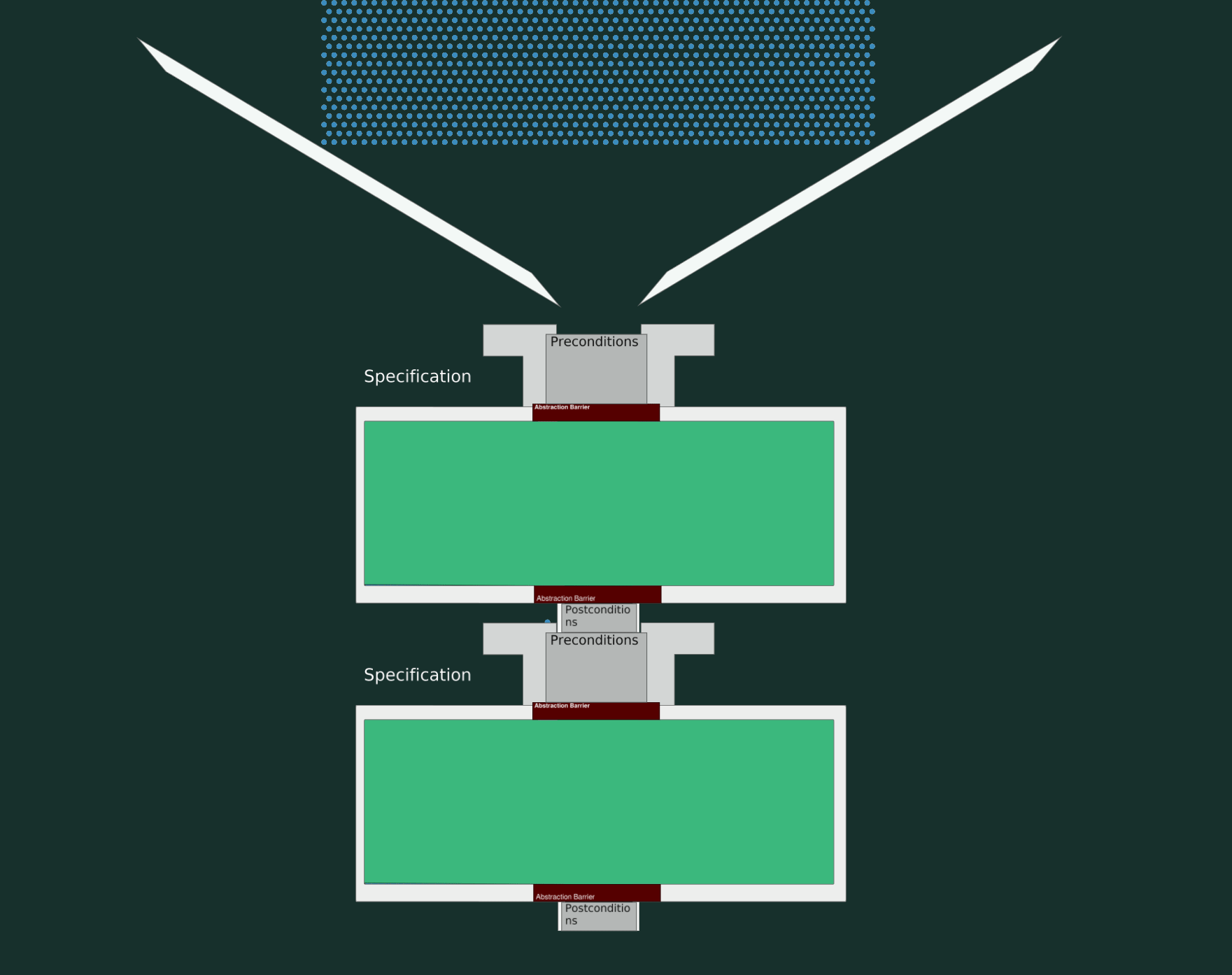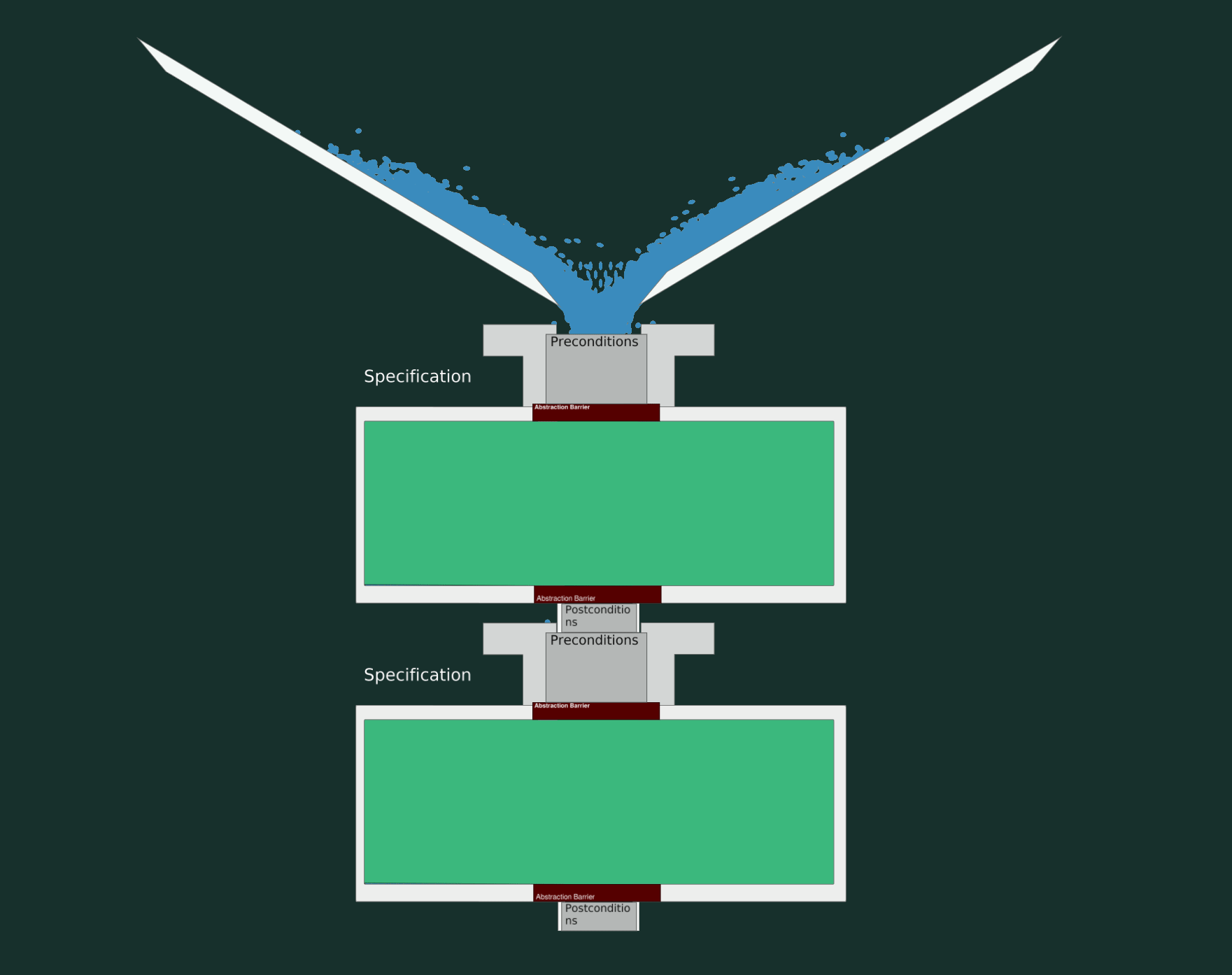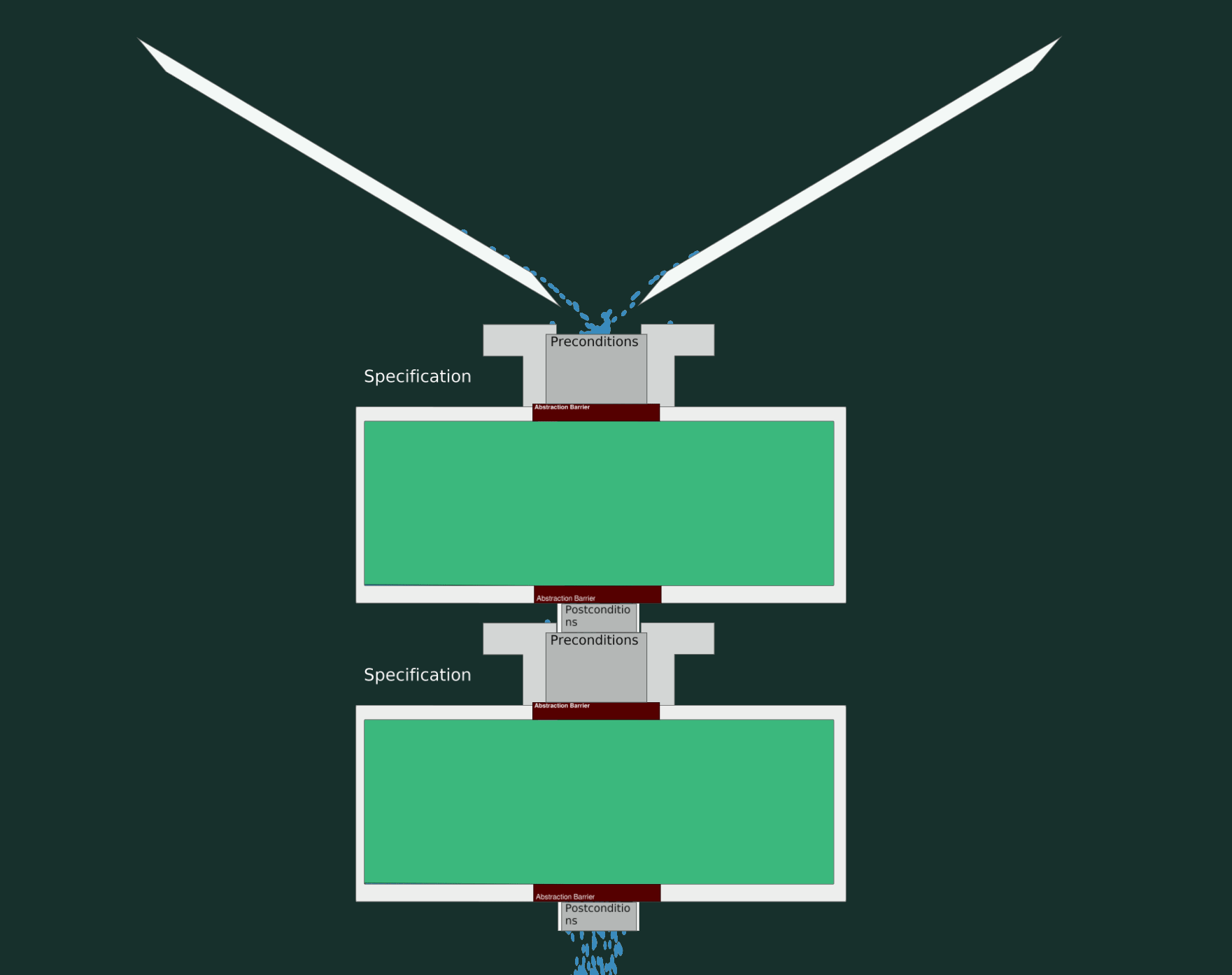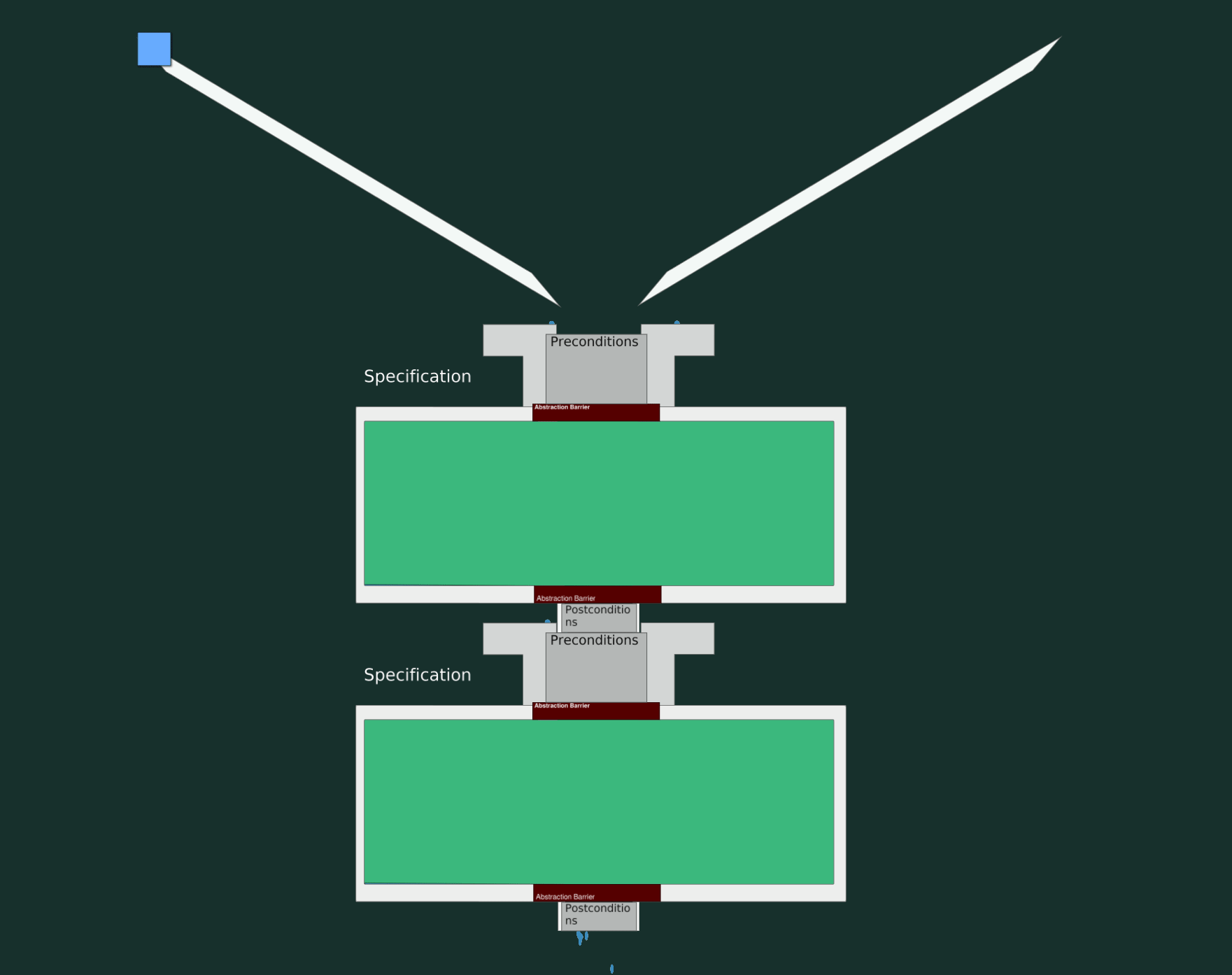
When we think about a single run of a program on particular inputs, then that is the level of runtime. These specific inputs are represented by waterdrops in our animation above.
For one possible value my program is correct
At the level of code, however, we are looking at program correctness for all possible runs. In our animation, this is represented by the water (all waterdrops). (Code also guides the inputs/water through the program, and this is represented by pipes that live within the outer pipes)
For all possible values my program is correct
At the level of logic, we think about logical statements that are correct for all possible inputs and all possible implementations.
This is the level of specification and it’s represented by the pipes in the above picture. We must learn to see the guarantees our functions need and generate (pre and post-conditions) as different from the current function implementation itself. More on that later.
For all possible values and all valid changes my program is correct
These ideas are very abstract, and when I first learned about them, I hoped there was some simple visual representation of what was going on. So I set a background task in my brain to work on this problem to find a good way to internalize this field of knowledge. After probably 12 months, with some failed visualizations on the way, I found something that is both simple, intuitive and accurate. And that is what I am sharing with you today.
The Pipe!
Pipes | The Gaming Gimmick Turned Software Hack
The idea of pipes in a programming context is not exactly ground-breaking. If you’ve done a bit of Linux command line or functional programming, you’ve probably met the pipe operator. But here we are going to use it to reason about program correctness.
So, in Pipe Land, as we said above, the three levels of code are represented by:
- Individual Water drops: The runtime level
- All the water: The code level
- Pipes: The logical/specification level
This will give us a great visual and intuitive understanding of how these levels interact.
With our Pipe visualization, you’ll see clearly why this can be the case (see bottom of the post).
Speed running the logical level of code
Let’s take a simple TypeScript function:
const add = (a, b) => a + bIs this code correct? …Well, what does it even mean for code to be correct? If we don’t have a specification(what we want to achieve), we can’t say anything about correctness.
We need a specification.
// Specification
// add is a function that takes two numbers
// and returns those numbers numerically added together
const add = (a, b) => a + bIs this code correct? By visual inspection, yes, the code is correct!
What about this code?
import { add } from "./add"
const hello_ = "hello_"
const world = "world"
const hello_world = add(hello, world)
console.log(hello_world)Is this code correct? and if not, where is the bug?
First of we (again) forgot to say what the aim(specification) of the program is.
We can probably guess that it’s to print "hello_world" to the console,
but we can’t say that for sure, so let’s add a specification.
import { add } from "./add"
// Specification
// This program prints "hello_world" to the console
const hello_ = "hello_"
const world = "world"
const hello_world = add(hello, world)
console.log(hello_world)It produces the correct output, so it must be correct… right?
Not quite… this is where the logical level of code comes in.
Let’s put the specification we have of add in the code.
import { add } from "./add"
// Specification
// This program prints "hello_world" to the console
const hello_ = "hello_"
const world = "world"
// Specification
// add is a function that takes two numbers
// and returns those numbers numerically added together
const hello_world = add(hello, world)
console.log(hello_world)add function?No we didn't! but our program still produces the right results... here’s the catch!
The problem is that, when we said that the program works, we weren't able to do that just by thinking about the specification of `add`. We had to use the current implementation of `add` to reason about the correctness of the program.
At this point, you might be thinking,
“So what? It works!”
Well, imagine if we decide, to tweak the add function. Perhaps our first implementation was a bit too basic and we want to improve it.
// Specification
// add is a function that takes two numbers
// and returns those numbers numerically added together
const add = (a, b) => {
if (typeof a !== "number" || typeof b !== "number") {
throw new Error("inputs must be numbers")
}
return a + b
}Same sh…spec! different implementation!
Whoops! Now our hello_world program where we use the add function springs a leak! This time at both the runtime and code level,
we’ve got a problem and must go back and patch it up!
Yet we didn’t change our specification, and both our old and new implementation of add are correct.
So what just happened?
Let’s pause for a minute here to make sure we’re all on the same page. The runtime level corresponds to a single run of the program that fails. The code level is all possible executions of the program/function/etc, which you could find using exhaustive testing.
Pipes and water | Avoiding Errors of Modular Reasoning
An “Error of modular reasoning”. That’s what we call a bug where a program works but doesn’t obey the specifications of code it uses. They’re a unique kind of bug that are hard to spot, appearing in programs that look like they’re functioning well until, one day, they suddenly break due to a logically correct change in some other part of the program.
Modular reasoning is:
Being able to make decisions about a module while looking only at its implementation, its interface and the interfaces of modules referenced in its implementation or interface. -source
So an error of modular reasoning occurs when we can’t verify the correctness of a program by just reading the code and looking at the specifications of the code it uses. Instead, we need to delve into specific implementation details that might give more guarantees or work with a broader set of values (like strings in our case) than what the specifications guarantee. Here is where you might hear a senior engineer saying:
Yes, this code is correct (or at least it works!), but only under assumptions that aren’t stable guarantees.
Every time you manage to get “a stable guarantee” into a PR review your seniority level goes up by one.
Pre and post conditions | Laying Down the Rules
- Preconditions: What must be true before a piece of code is called
- Postconditions: What holds true after a piece of code has been called
Anything else is an implementation detail!
add function:
{} brackets capture what needs/is true at a certain point in the program
// precondition: {a is a number, b is a number}
const add = (a, b) => {
if (typeof a !== "number" || typeof b !== "number") {
throw new Error("inputs must be numbers")
}
return a + b
}
// postcondition: {return value is a numerically added to b}But better still is to think of it without the implementation details. Like this:
// precondition: {a is a number, b is a number}
const add = (a, b) => { ... }
// postcondition: {return value is a numerically added to b}This is the essence of the add function! Any implementation that meets these conditions is valid.
Hoare logic: Levelling Up Code Reasoning
The logical statements I showed above are part of a formal method called Hoare Logic (plug: which we teach in our course). Hoare Logic allows us to reason about the correctness of our programs by examining the pre/postconditions and code. It gives us rules that tell us what the postconditions of a function are, given its preconditions and code, or conversely, the preconditions given the postcondition and code. This means that we can use Hoare Logic to think (and prove the correctness) about specifications.
When I first took our Mirdin course (yes, I started as a student), I was blown away by Hoare Logic, and it was very useful in getting me away from the code and thinking about the design of the program instead. That said, there are a lot of rules in Hoare Logic but how do we go from thinking in rules to intuition from where the rules would be obvious?
Let’s revisit our initial implementation of add together with the spec we have been using:
Let’s take a closer look at our original implementation of the add function,
along with the specification (pre/postconditions) we’ve been using:
// precondition: {a is a number, b is a number}
const add = (a, b) => a + b
// postcondition: {return value is a numerically added to b}The above spec is just one of many our code can support, showing a (many-to-many relationship between implementation and specification.) However, it’s important to note that our current precondition (the rule about what must be true before the code is run) is not the weakest(most relaxed/flexible) condition that this implementation can handle.
The weakest precondition is that a and b are any values for which a + b is defined.
(which in JS is number and string plus anything that can be cast(converted) to one of the two, which is pretty much anything🙃)
If we went with such a generic precondition, concat would be a better name.
To make our initial program correct on the logical level and not contain an error of modular reasoning,
we can change the precondition to be:
// precondition: {a and b are both strings or numbers}
const add = (a, b) => a + b
// postcondition: {
// IF a and b are numbers
// return is a numerically added to b
// OTHERWISE
// return is a string concatenated with b
// }Weak and Strong Conditions
- A condition is weaker if it needs/gives less guarantees.
- A condition is stronger if it needs/gives more guarantees.
Some rules (don’t try to memorize them):
- If a new precondition is weaker than the old precondition, it is a non-breaking change.
- if a new postcondition is stronger than the old postcondition, it is a non-breaking change.
Instead of memorizing the rules, we will now use pipes to drive them home and make it obvious. Then later you can derive the rules from your intuition.
The bug in the code we had earlier was that we did not respect the specification of add, we used the implementation instead. However, one way to “solve” this is to change the specification to work with strings as well.
Will this be a breaking change or a non-breaking change?
think and answer before you continue
Answer
It will be a non-breaking change, because the new precondition is weaker than the old precondition. Before, we only acceptednumber as input, now we accept number or string.
{number} => {number || string}
The old precondition implies (logical implication, learn about it in the course) the new precondition, so all old callers that meet the old precondition will also meet the new precondition.
{old_callers} => {number} => {number || string}
Okay, here comes the exciting part: how can we visualize all this?
Next in the pipeline, pipes!
Visualizing with Pipes!
Imagine pipes - like in Super Mario.
![]()
The key feature of pipes is that they can stack on top of each other, each fitting into the next.
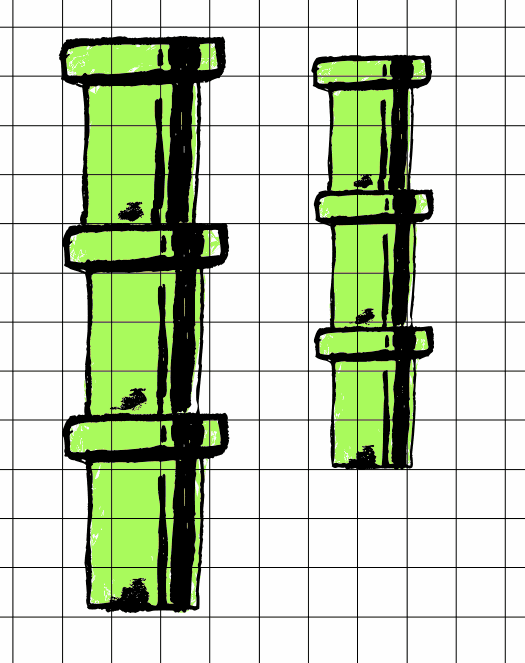
These pipes represent our different specifications. They take in inputs and produce outputs. If we want to change our pipes/specifications, there are two ways we can do it without disrupting old callers/pipes. The width of the pipes corresponds to the strength of the specification.
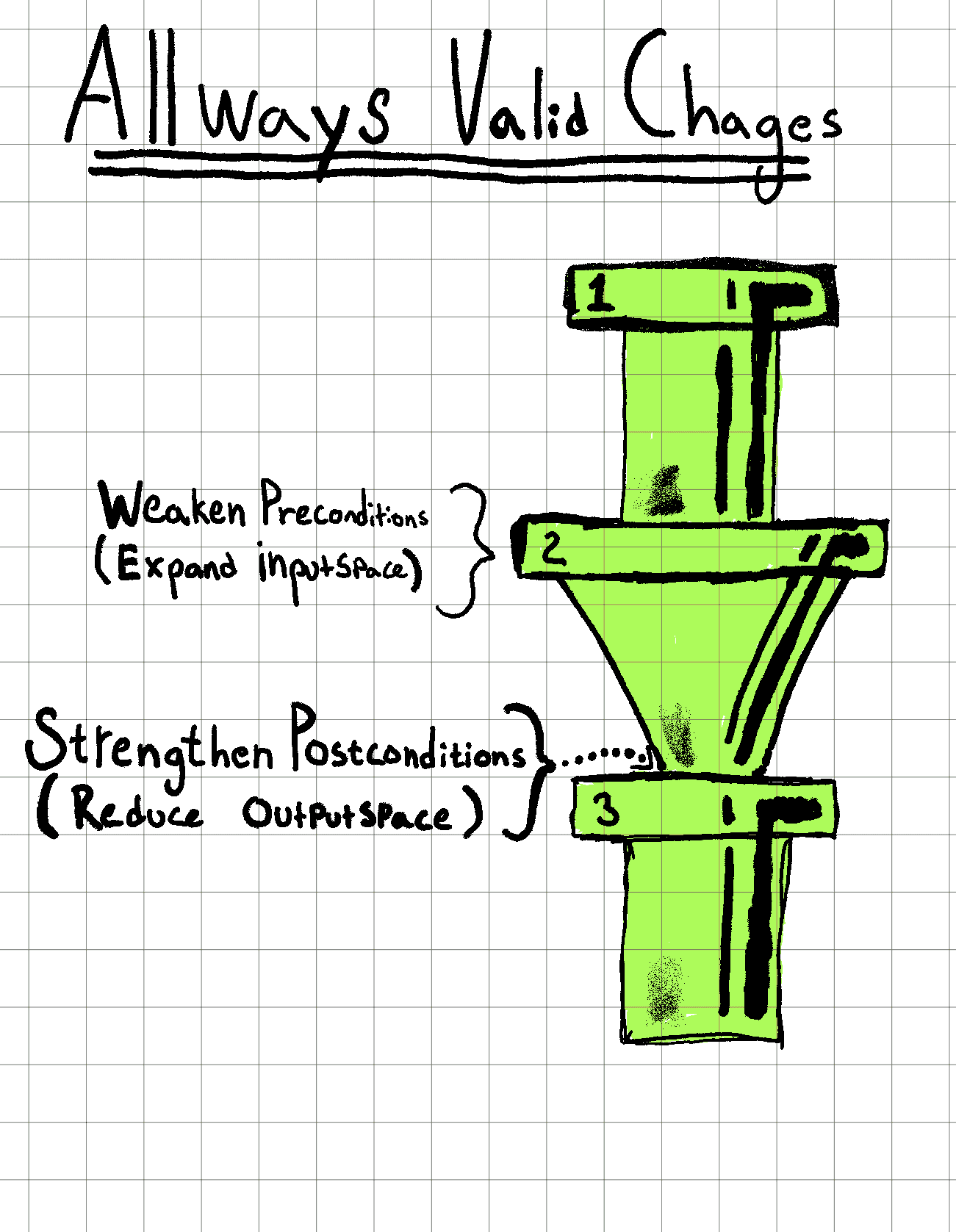
However, the opposite alterations would always result in a breaking API change. This is a logical level statement; it remains a breaking change even if all actual current callers continue to function.
Example: In the above image the third pipe(3) could now strengthen its precondition since there is space to do so, however, this would still be a breaking change because this pipe can be used in many other setups where such changes would not work. We need to respect every potential caller and think about the ghost pipes that need our current exact requirements.
Ask yourself this, if you change a backend API, but you know all callers and control them, and the old callers will keep working under your new stricter API, is it still a breaking change?
Let’s now look at a series of animations to work up this intuition.
Specifications Composition
Base Spec
Recap, Here two specs are combined (logical-level). The water represents all possible runs (code-level),
while each droplet symbolizes a single run (runtime-level).
We see the specs fit together and all the water passes through without any leakage so we have a working and correct program.
A Valid Change
In this scenario, let’s modify the specifications to accept a broader input range (weaker precondition) and return a narrower output range (stronger postcondition).
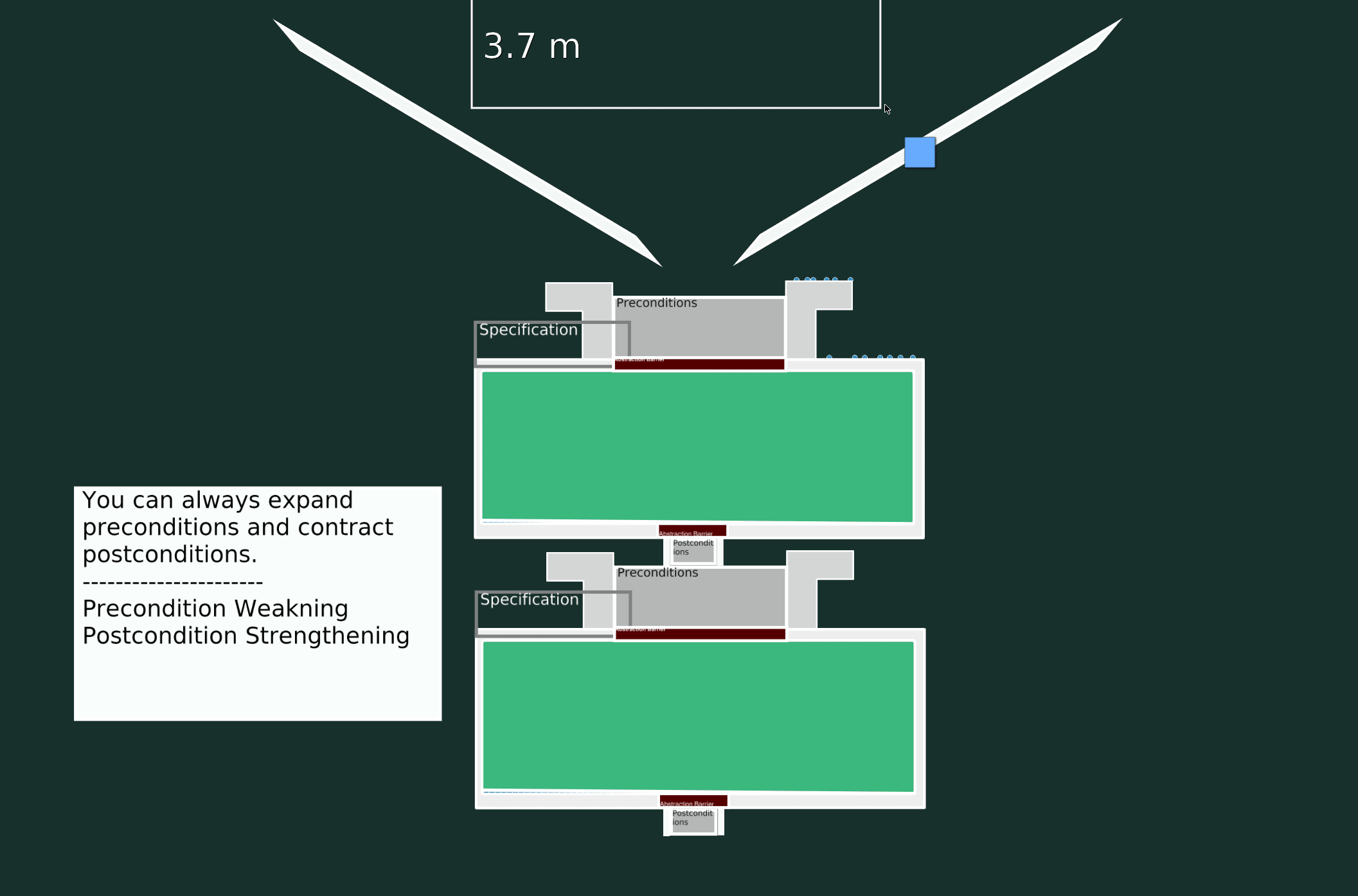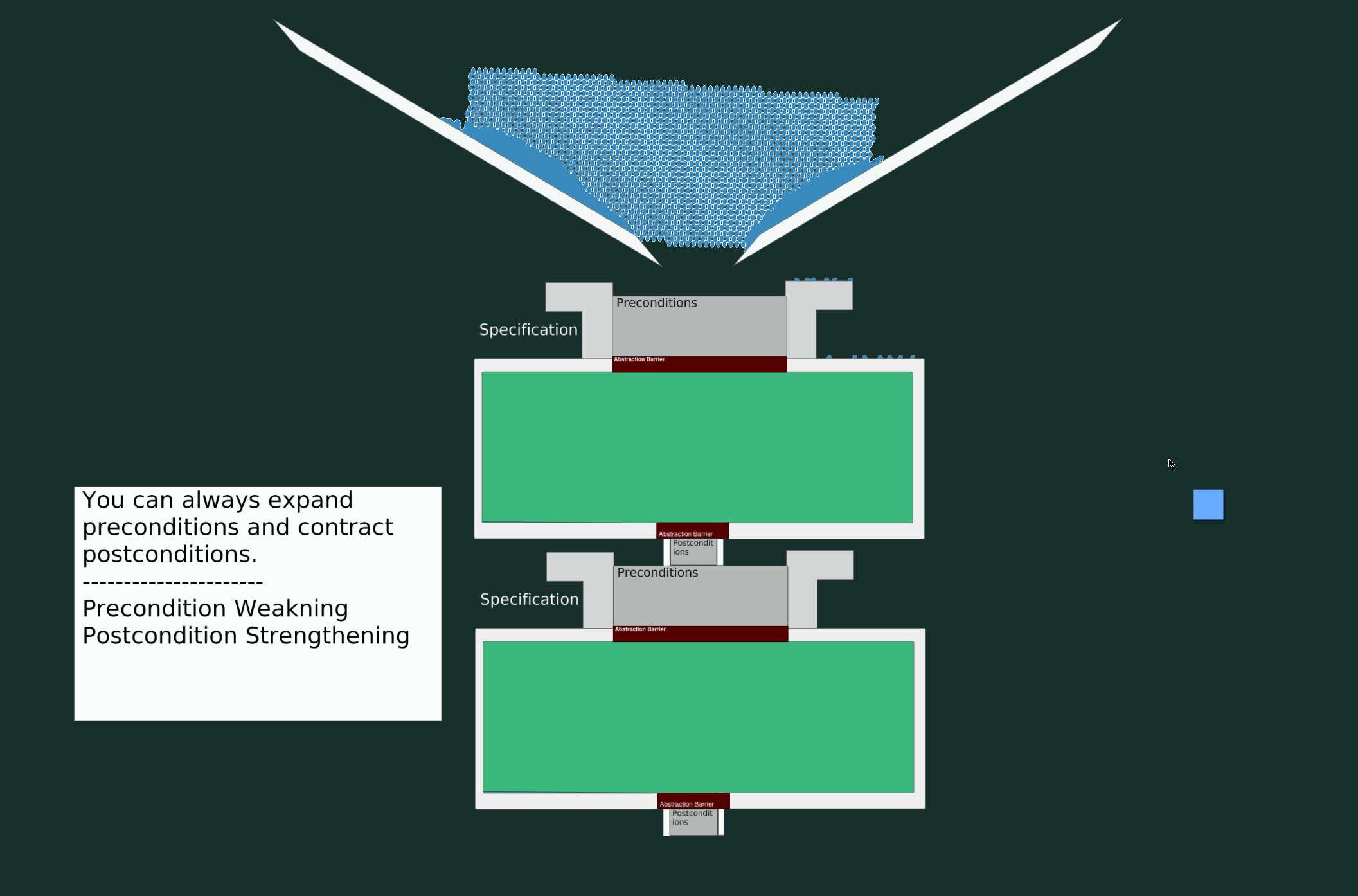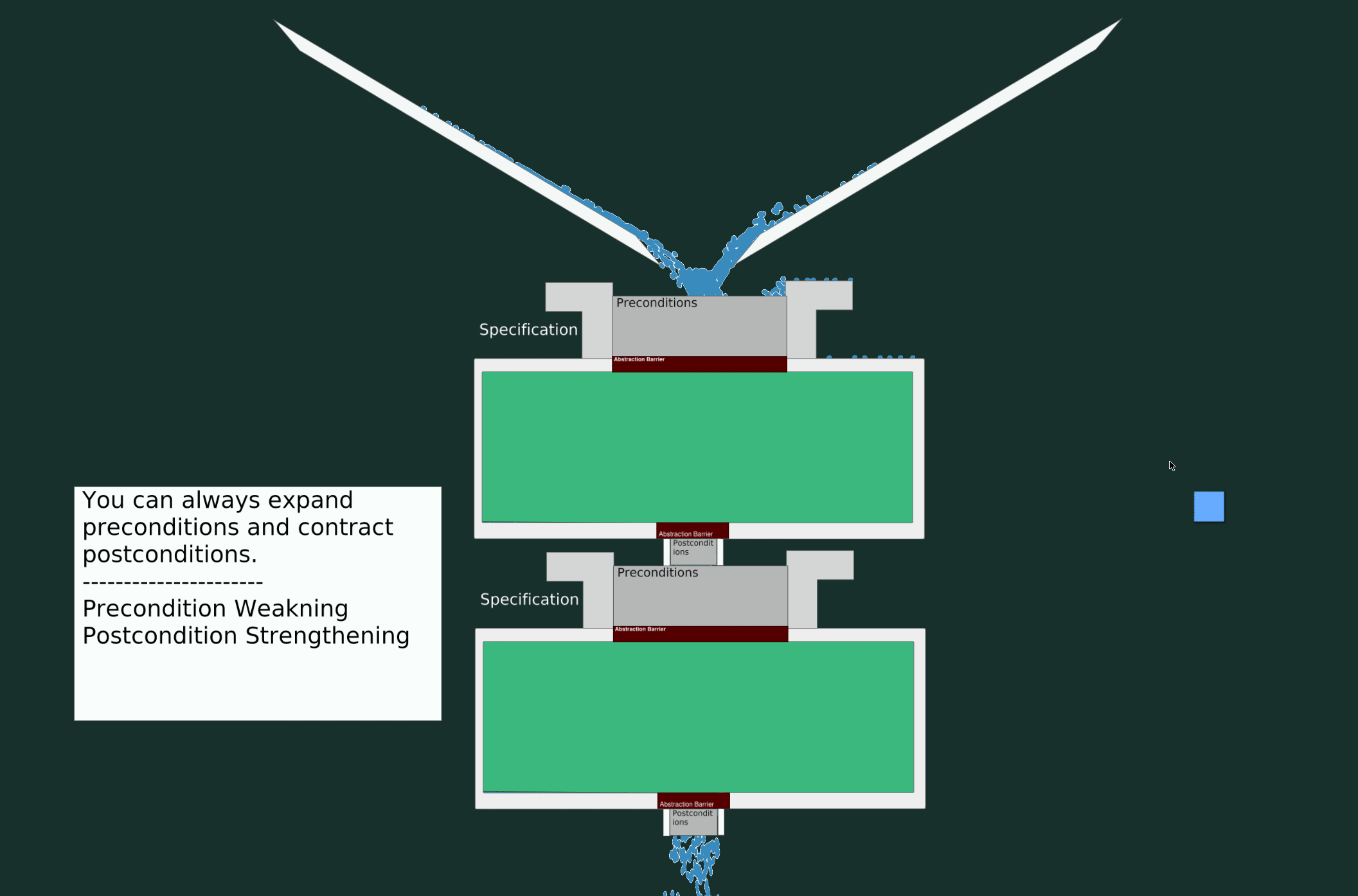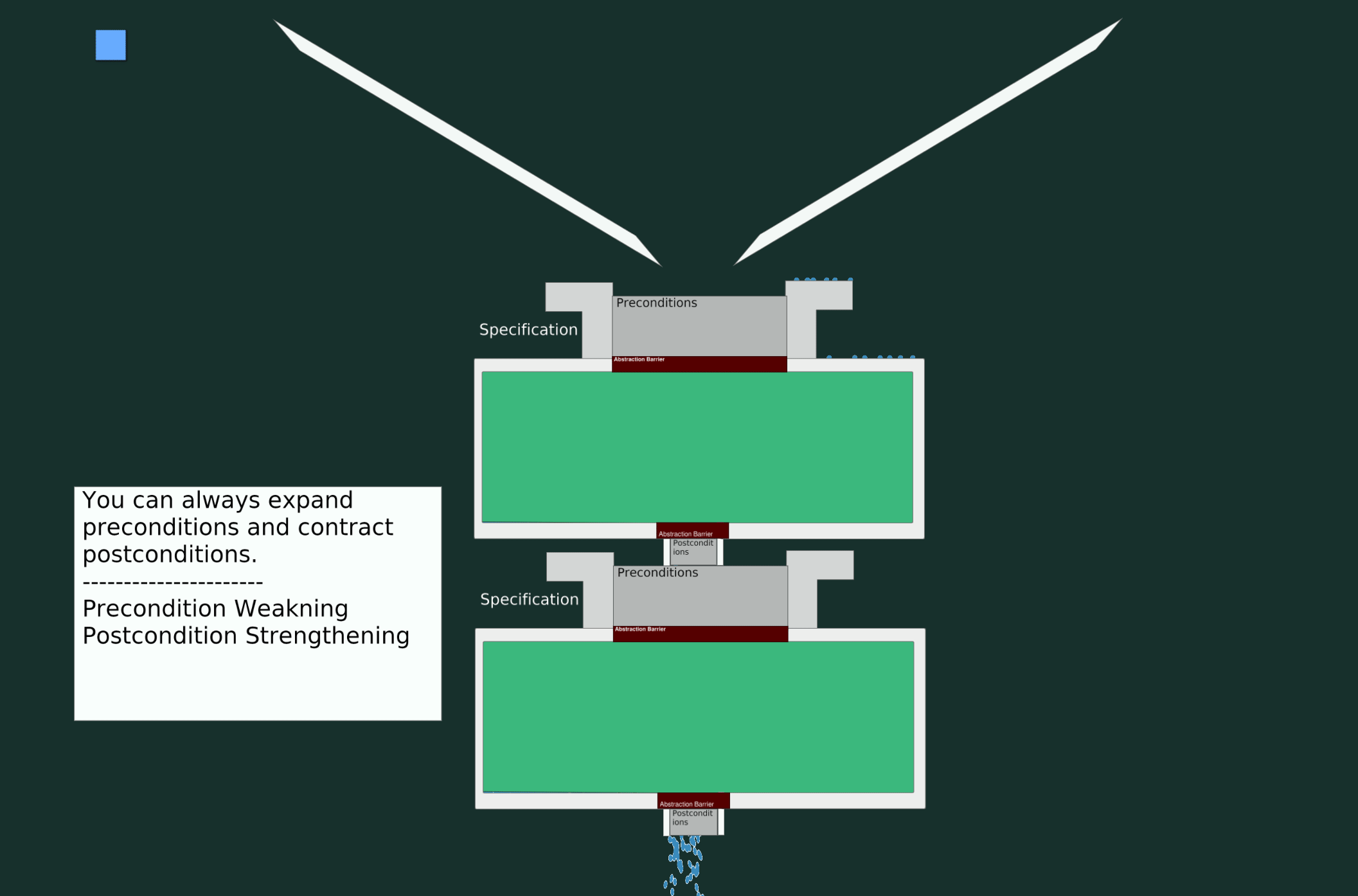
A Breaking Change
Now, let’s see what happens when we try to give fewer guarantees (weaker postcondition) and accept a narrower input range (stronger precondition). As depicted, this leads to “leakage” and hence, a malfunctioning program.
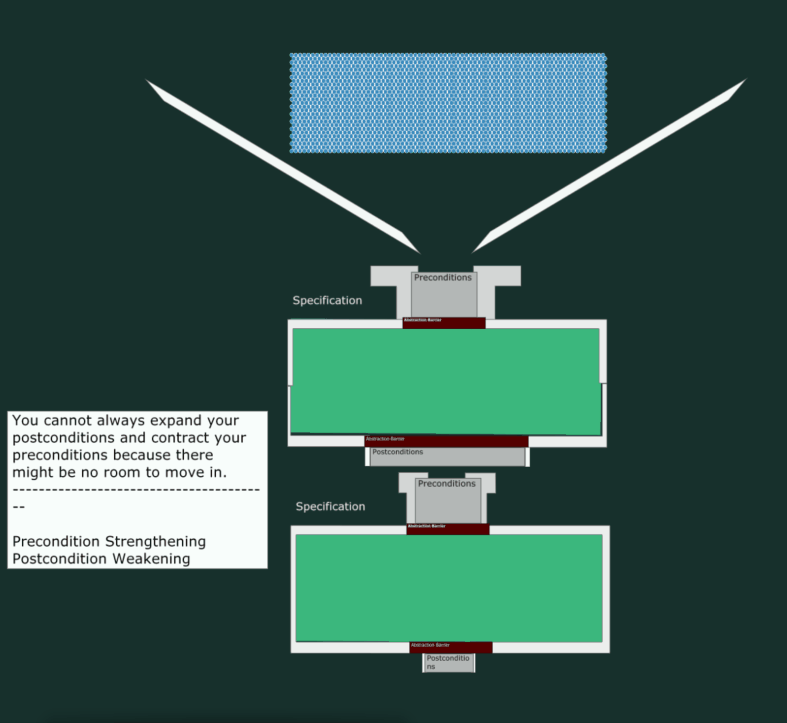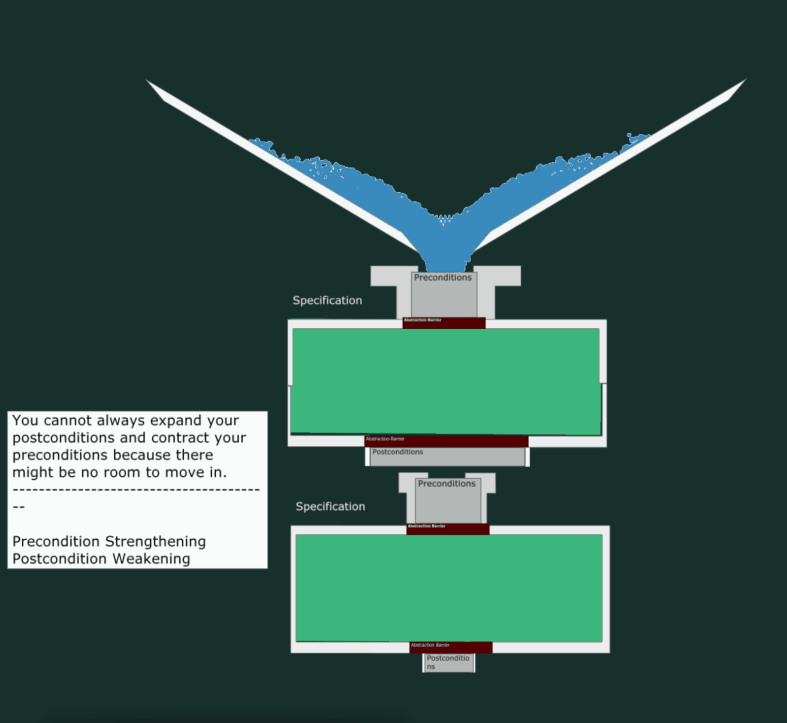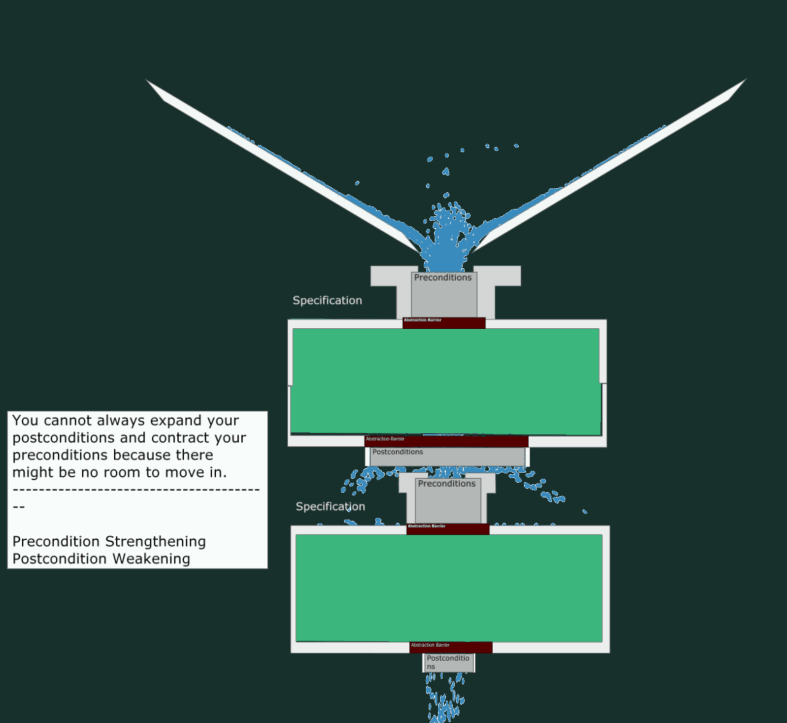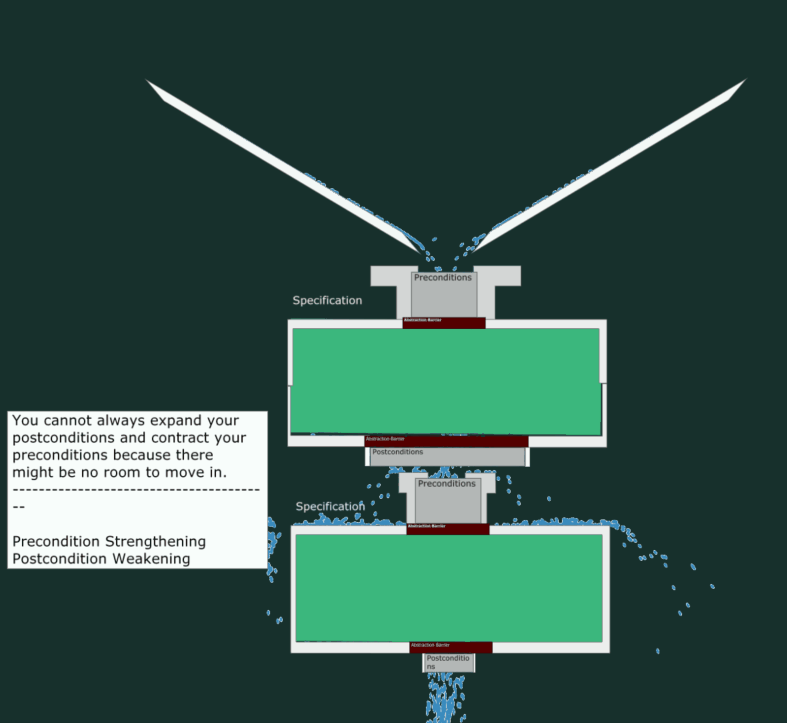
Where’s the Code?
To visualize the code we need more pipes! The outer pipe creates a boundary within which your implementation must live. If your specification asserts that it will output numbers less than five and your code generates numbers less than three, that implementation is still valid.
What If I Told You There Is No Spec?
Specifications do not really exist! They are just an idea. Though the more powerful the language the more of it we can embed (see Coq for full embedding).
The specification pipes we’ve been seeing are not as rigid as they might appear, they are actually just air. So, what guides the input (the water)?
The answer: THE CODE!
Let’s have a look inside the pipes.
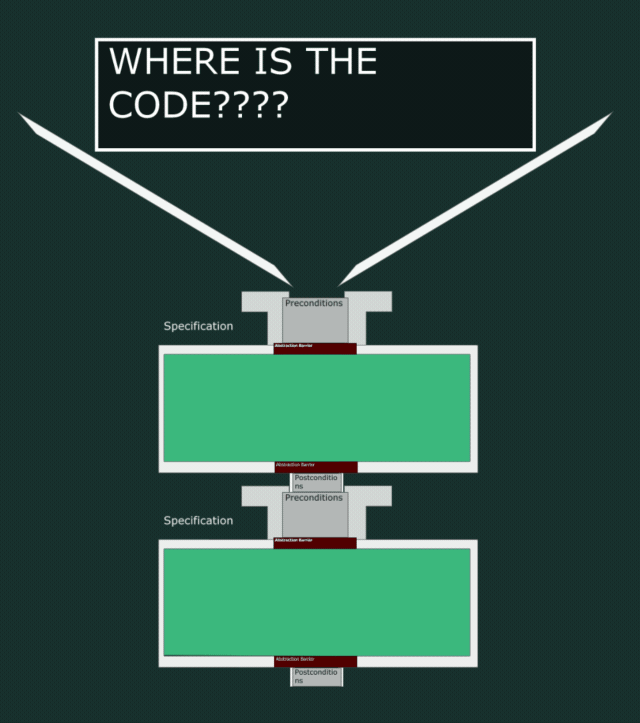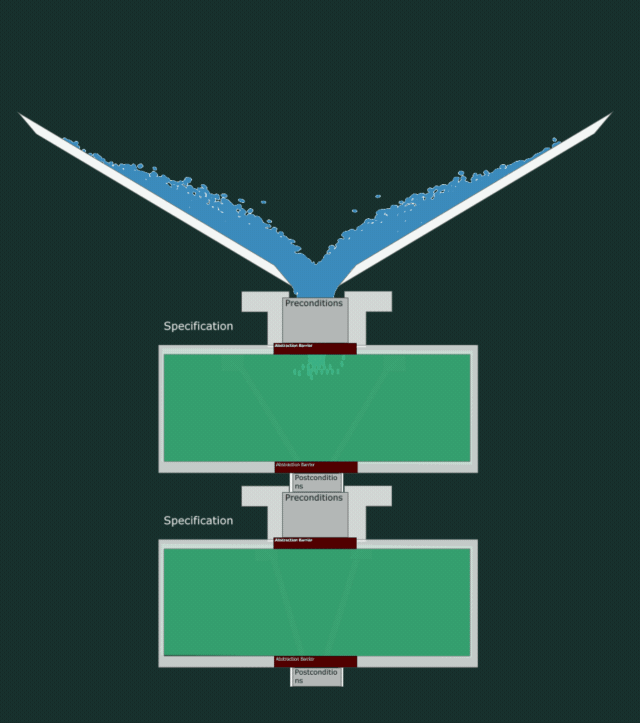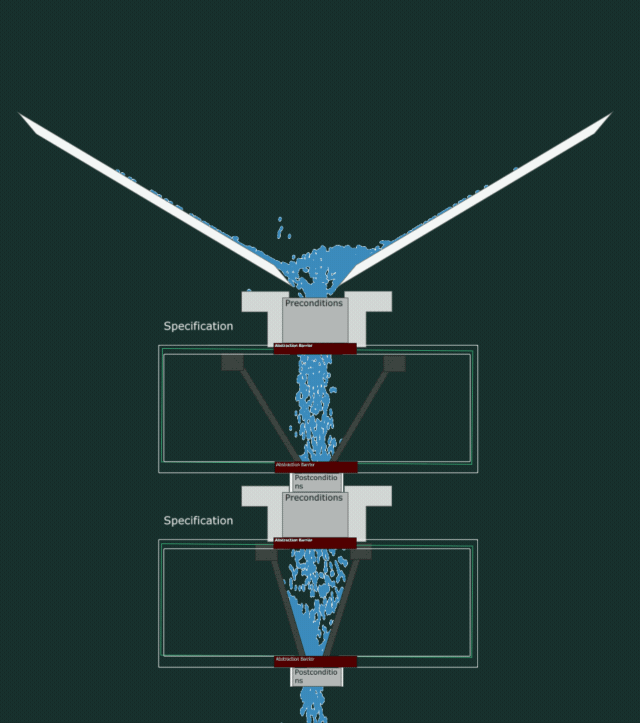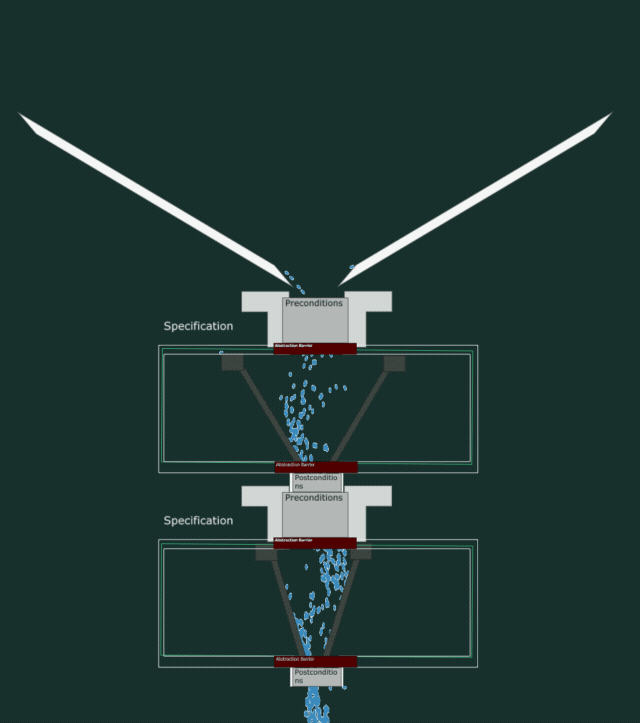
The code needs to make sure it at least can collect all the incoming water that the precondition wants to let in, and not spread it wider than the postcondition wants to let out. All while containing no leaks.
The specification outlines the boundaries within which our code needs to live, but it’s the code that must adhere to the specification.
In the below animation, you can see how the water leaks out even though the specifications match. This is because this implementation does not respect the postcondition and is too loose in what it lets out.
A buggy implementation
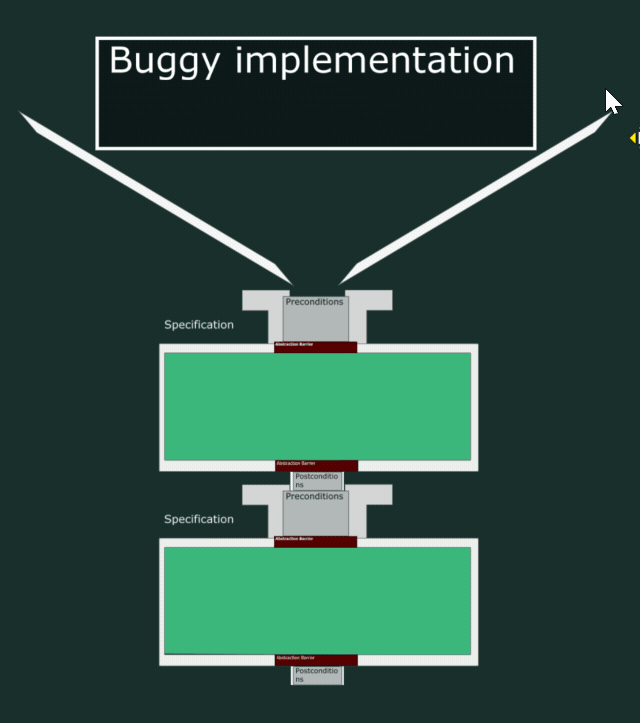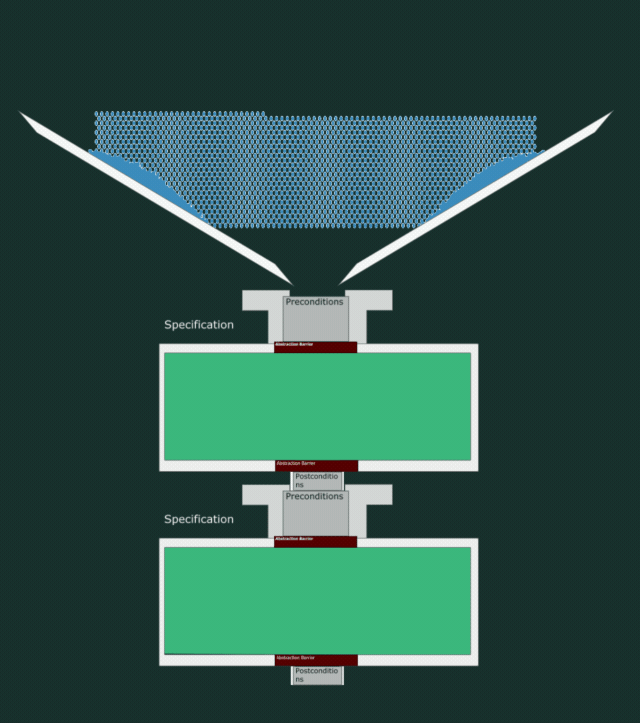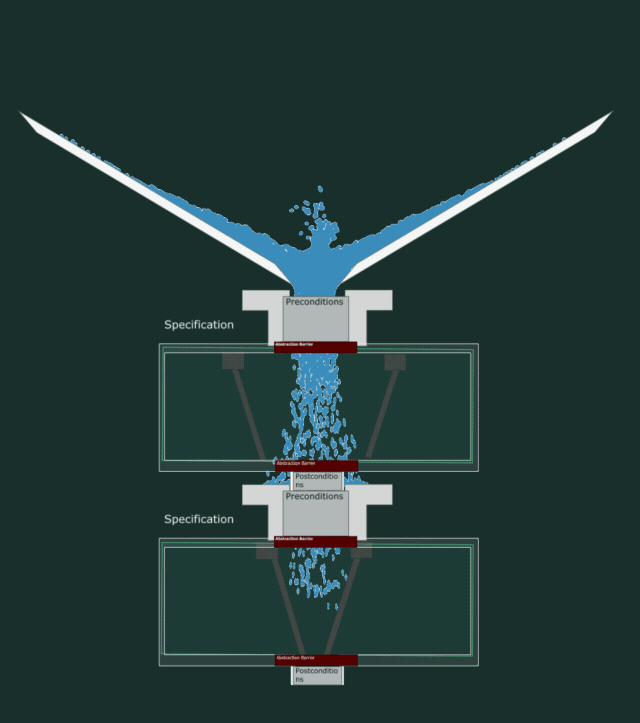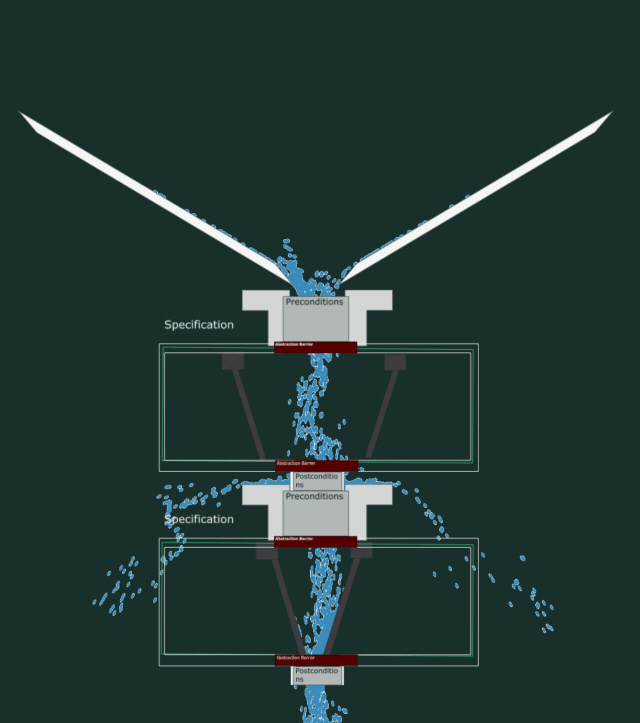
The interplay between specification and code
The interplay between specification and code is that if your specification does not give too many guarantees and accepts every value under the sun, then the code has more room to move.
In Hoare Logic we talk about precondition strengthening and post-condition weakening, and how that relates to a form of modularity.
- The output of your precondition is the input of your code
- The output of the code is the input to the postcondition.
So the relationship between the precondition and the code is the same as between the postcondition of one spec and the precondition of the next spec.
This gives rise to much of the rigidity in software development. You can always broaden your precondition, but the implementation may also need to be modified. If your code is forgiving but your specification is strict, you can modify the specification without changing the implementation (as with add).
Comprehension questions
The weaker we make a condition the wider the pipe gets, and the stronger we make a condition the narrower the pipe gets.
When talking about Hoare Logic we sometimes talk about the weakest precondition and the strongest postcondition. To get the weakest precondition we need to know the code and the postcondition. To get the strongest postcondition we need to know the precondition and the code.
So with this new understanding, what would it mean to have the weakest precondition or the strongest postcondition?
Answer | The Strongest Postcondition
The strongest postcondition is the strongest guarantee that we can form from the current code and the precondition.
Answer |The Weakest Precondition
The weakest precondition is the least amount of guarantees we need from the input to still have the code imply the postcondition.
Visualizing Errors Of Modular Reasoning
Let’s now revisit the statement from the start of the post (the primary idea conveyed in The three levels of software)
A program that never goes wrong can still be wrong.
Let’s now see how we can visualize this using our pipes. We will see that it’s maybe not so strange a concept after all and it is just a natural emerging fact of the interplay between multiple pipes(specs) and sub-pipes(implementations).
Two Types of Errors in Modular Reasoning
-
Depending on a Stricter Output Than the Specification Guarantees
Example: When the game SimCity was created, there was code that used memory after it was freed, but the program still worked by coincidence because the then current implementation of the memory manager in the Windows operating system was stricter than the specification. The Windows operating system did not touch the memory after it was freed. Everything worked until a new release of Windows years later. (Microsoft fixed this issue by patching Windows. Joel Spolsky, How Microsoft Lost The API War) -
Depending on Being Able to Use Looser Input Than the Specification Guarantees
If the current implementation is more forgiving than the specification guarantees. Depending on that is also an error of modular reasoning. Like with ouraddexample, the behavior we got when calling the function with the wrong arguments is not a stable guarantee for future valid changes to the function’s implementation.
Both errors are something that will only come up when code you depend on changes, so there are no observable issues that can be found in the current code.
Depending on the languages it’s possible to embed the spec or parts of it in the types. Then these types of logical errors will become compile-time errors. It’s also possible to check for specification violations at runtime, this is what design by contract does.
Error Of Modular Reasoning Visualized
This code has an Error Of Modular Reasoning. The second function depends on the current implementation and not the specification.

Now if we do a valid non-breaking change to the first function, we still get a runtime error in our program.
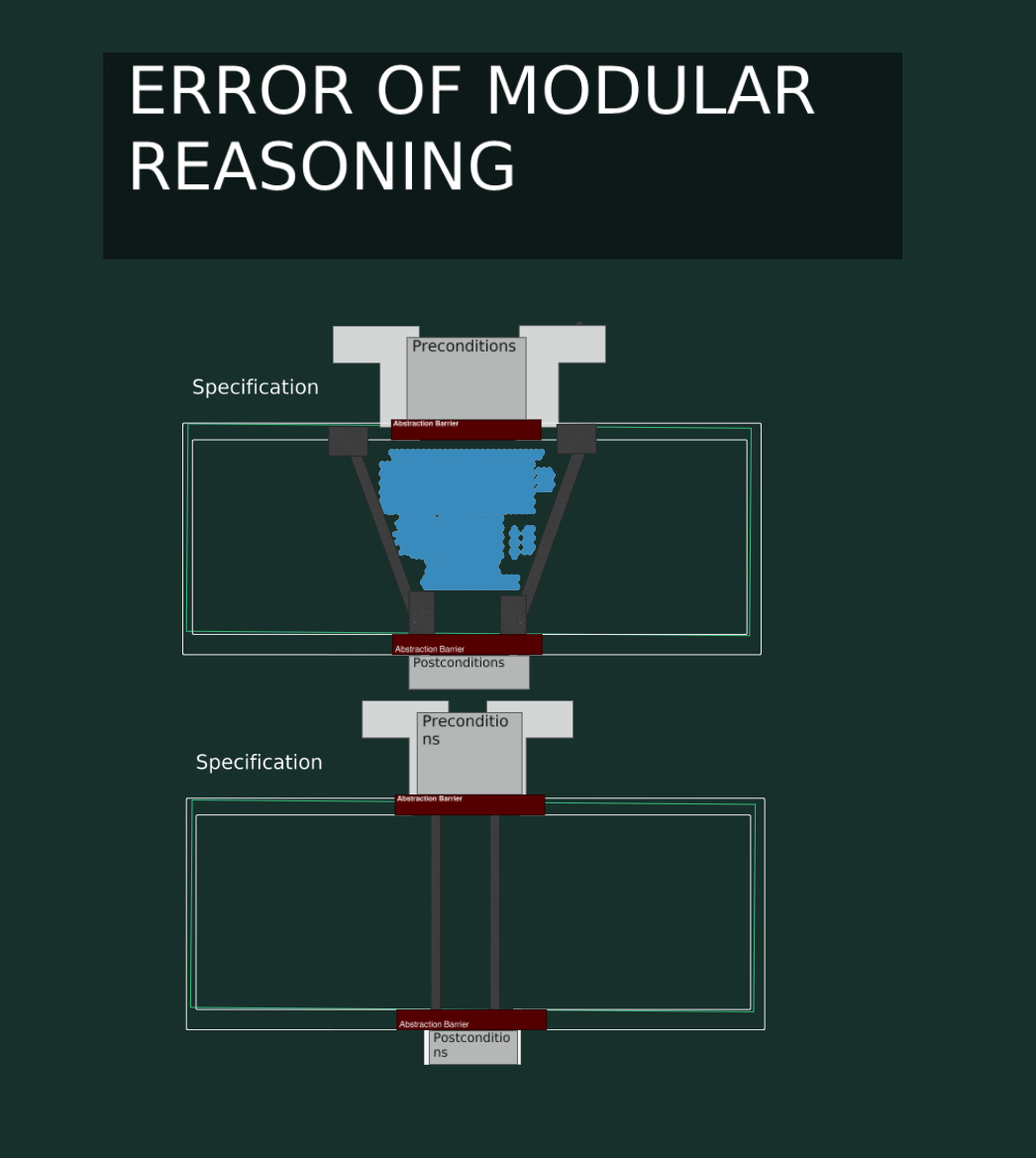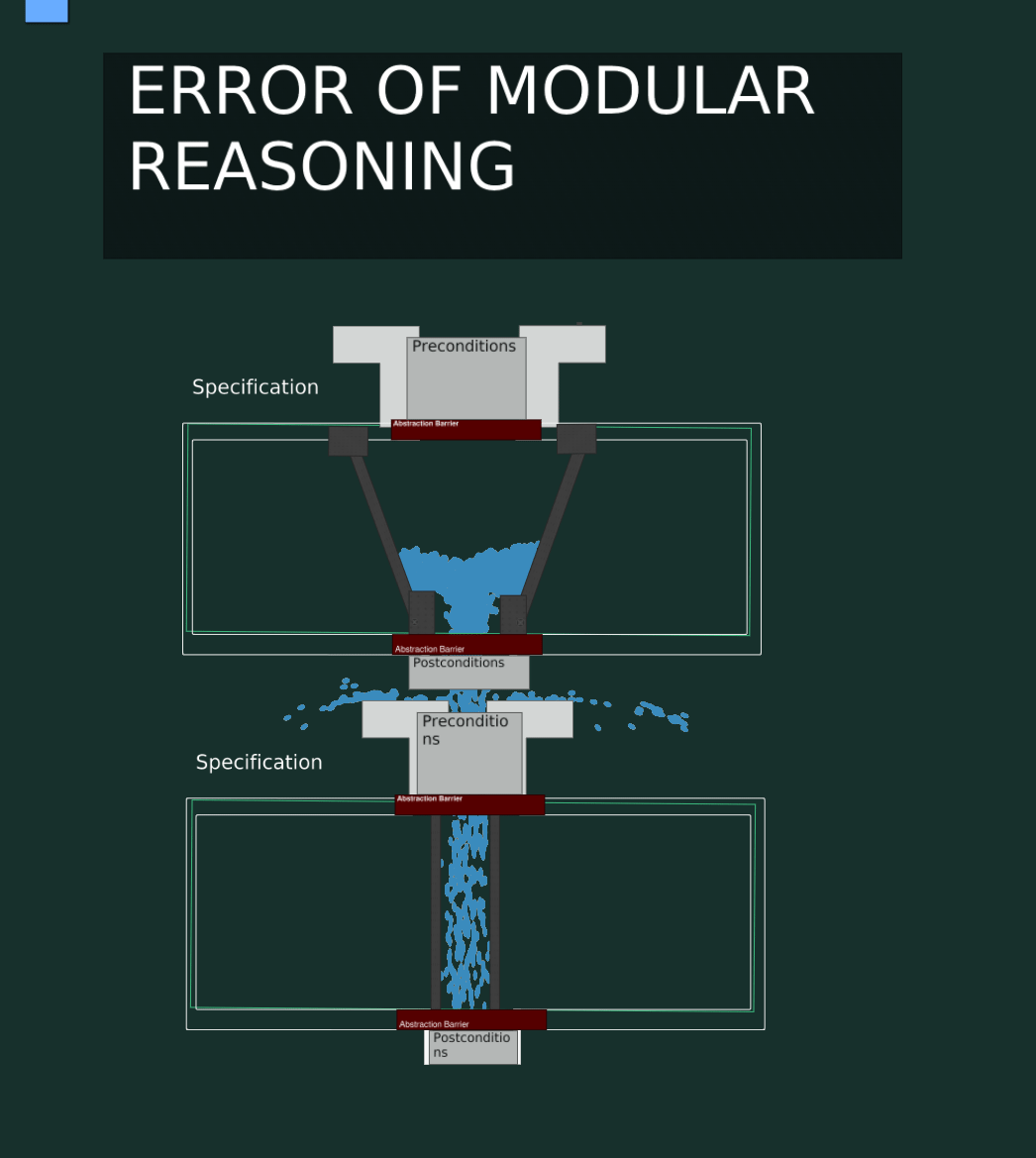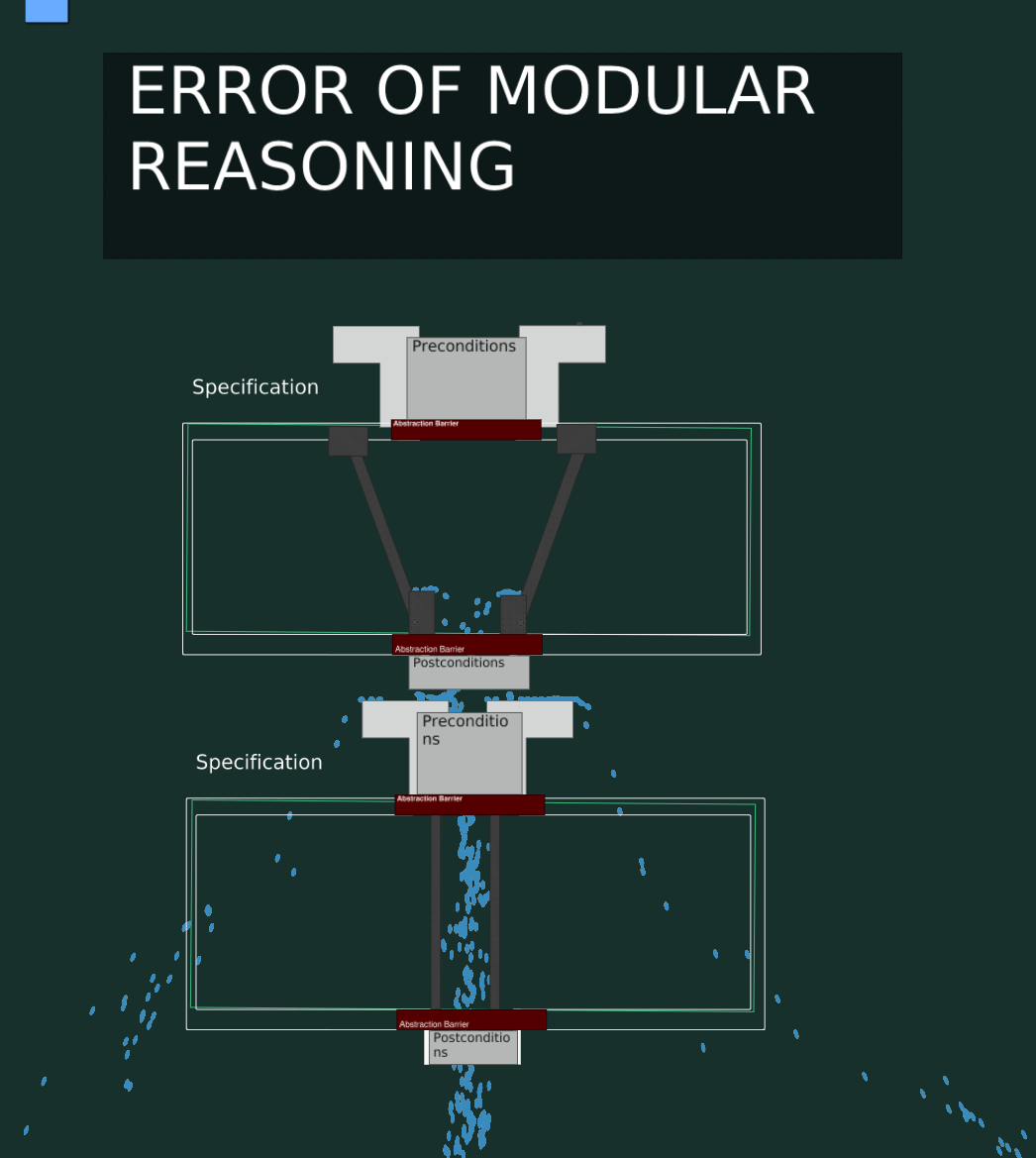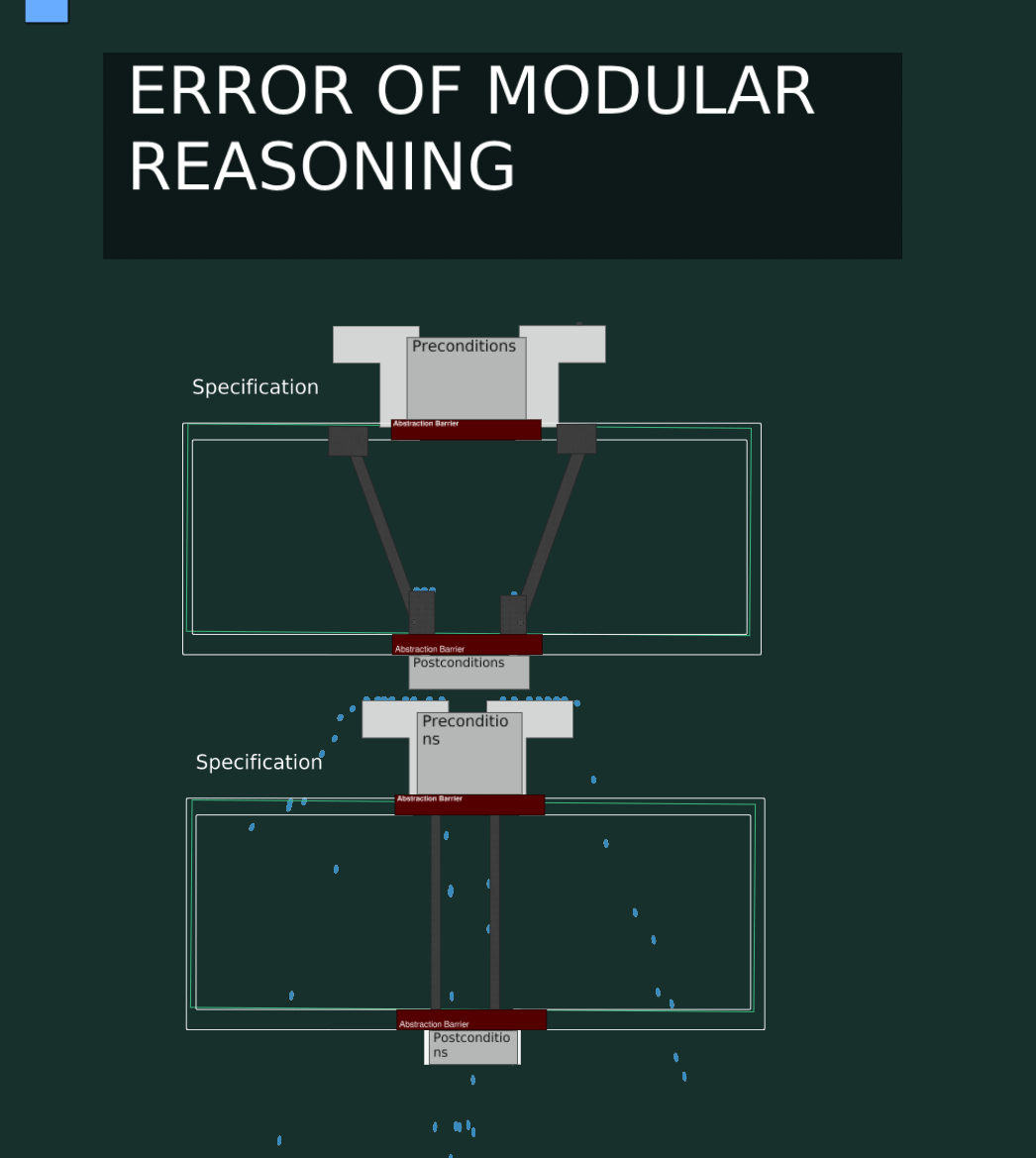
This is of course because the second function depends on implementation details of the first function, which are not stable guarantees (part of the spec).
Thinking about the boundaries of pieces of code makes it much easier to point out where the bug is, and what code should be changed to fix it. In the above case, it’s clearly the second function that is incorrect.
Stable Guarantees
Senior programmers talk about stable guarantees. What this means is that we only depend on what is guaranteed by the specification. “What if there is no specification?” I hear you say. Well, most code do not have specifications, so what do we do then? All code has a specification even if it’s not written down. It’s just that the specification is implicit in the code and the specification might be different in different engineers’ minds.
A Tale of two engineers:
-
“Hey! You broke the API! The returned list is not in the same order anymore”.
-
“No this was not guaranteed by the API, you should not depend on that.”
-
“Well it’s a reasonable thing to expect from a list, and altering it is a breaking change.”
-
…etc!
So start talking about specs and align your team(s) on what is guaranteed or not for different parts of the system.
End
Understanding the interplay between specifications and their implementations is key to good software engineering. It’s important to note that even when your code seems to work perfectly, it could still contain hidden errors due to issues in modular reasoning.
Junior Engineer: “I have checked all the places where the code is used and it works!”
Senior Engineer: “Well…”
I hope that these pipes can help you visualize the logical level of software easier and help our students with Hoare Logic.
Happy coding!
Q & A
Question: “This code is untyped! if we had types you would not be able to call add with strings in the first place. Are types on the logical level?”
Answer: Types embed some of the logical-level in the code-level. but not all (that depends on the power of the type system though)
Question: “Should you make your implementation act as close as possible to the specification?”
Answer:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody. — Hyrum’s Law

So what gives? if your code gives more guarantees than the spec says, then some users will surely depend on that. And if you change the code to be more in line with the spec, then you will break those users (boohoo). Go famously made their map iteration random, because a lot of users were writing code depending on iteration being in order. Something that was not guaranteed in the spec, but was the case in the implementation. So they randomized the iteration order, to just not imply that stricter spec. And be open to more optimizations in the future. https://stackoverflow.com/questions/55925822/why-are-iterations-over-maps-random
Is it totally possible to do similar things where, for example, your current implementation is sync but you don’t want to guarantee that in the future, you can make it trivially async now by wrapping the return value in a promise (JS datatype). Then you can change the implementation later, without breaking the spec.
When you stake out your spec, you are creating space to move in. Do not give too many guarantees or be too nice with possible inputs from the get-go. You will have to honor that forever or break your API, don’t do that. This is basically counter to Postel’s law (a.k.a: ‘the robustness principle’), which to me sounds like a recipe for frail software (ironically enough).
Question: “Pre/post-conditions can be much more complex than can be represented with just water and pipes.”
Answer: Our current analogy takes us pretty far, but in reality (if anything is real) the shapes of the inputs/outputs are multi-dimensional. Thinking in the simple 2D plane is good enough for our needs. And the rules of logical implication in the 2D plane are the same as in the multidimensional space.
Acknowledgments
Big thanks to JunHong (Nemo) Yap, Christofer Ärleryd, and Jimmy Koppel for their invaluable assistance in both writing and editing this post.